
口袋AI本地大模型软件官方版 v1.6.7手机版
系统:Android 大小:23.6M
类型:手机工具 更新:2025-02-19
系统:Android 大小:23.6M
类型:手机工具 更新:2025-02-19
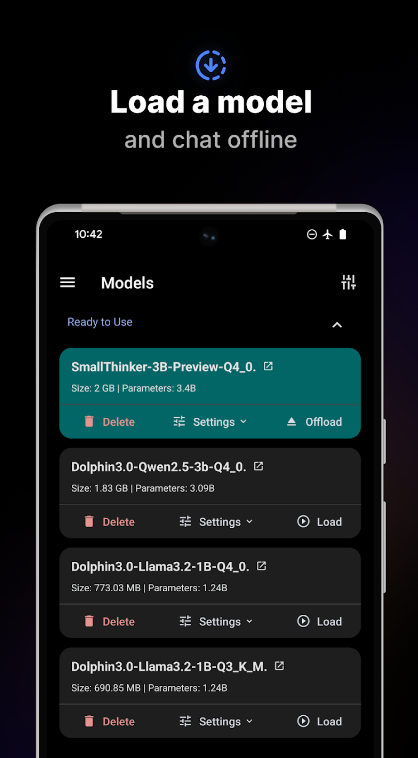
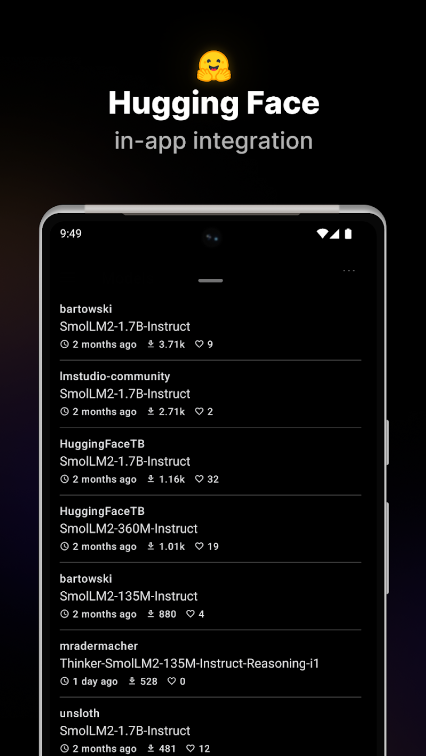
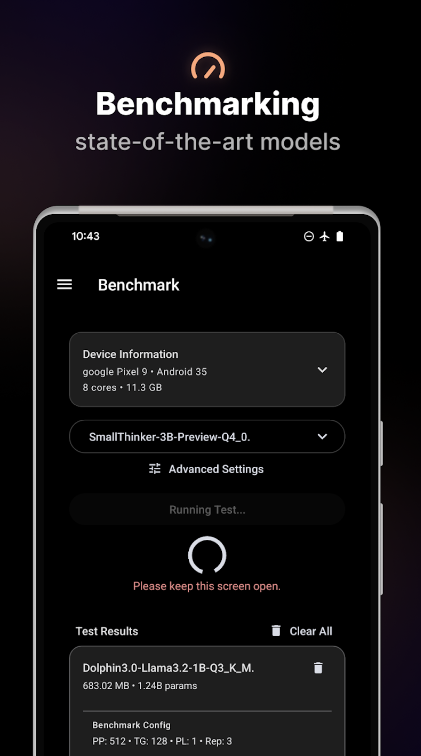

口袋AI本地大模型软件官方版是一款可以在本地离线运行的AI软件,软件无需互联网连接,就能直接与AI模型进行互动,这一特性确保了对话的私密性和安全性,可以在软件里直接使用包括Deepseek在内的软件,所有对话都在本地设备上处理,不会上传至云端从而保障了用户数据安全与隐私!

离线 AI 助手:在手机上直接运行语言模型,无需依赖互联网。
多模型支持:下载并切换多种 SLMs,如 Danube 2/3、Phi、Gemma 2、Qwen 等。
自动管理内存:后台运行时自动卸载/加载模型,优化设备性能。
自定义推理参数:调整系统提示词、温度、BOS token、对话模板等设置。
实时性能监测:查看 AI 生成响应时的每秒处理 Token 数和单个 Token 处理时间。
Hugging Face 集成:直接在应用内搜索 GGUF 模型,支持收藏或下载。
安全私密:所有对话均在本地处理,数据不会上传,确保隐私安全。
- 离线聊天:直接在您的设备上与高级人工智能模型交互,无需互联网连接。
- 安全和私密:您的数据永远不会离开您的设备。所有对话均在本地处理,提供安全性和安心。
- 基准测试:在手机上对模型性能进行基准测试并与社区分享。
1、下载模型,点击汉堡菜单
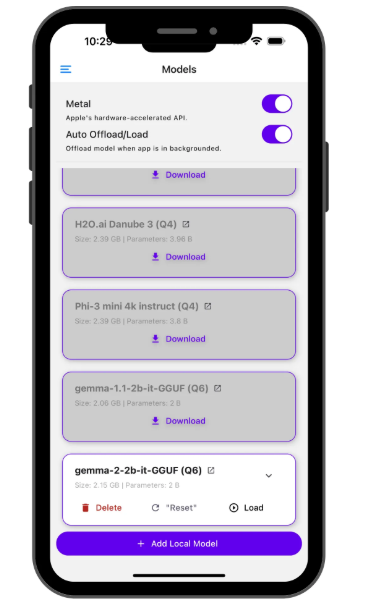
2、导航到 “Models” 页面,选择您想要的型号并点击下载
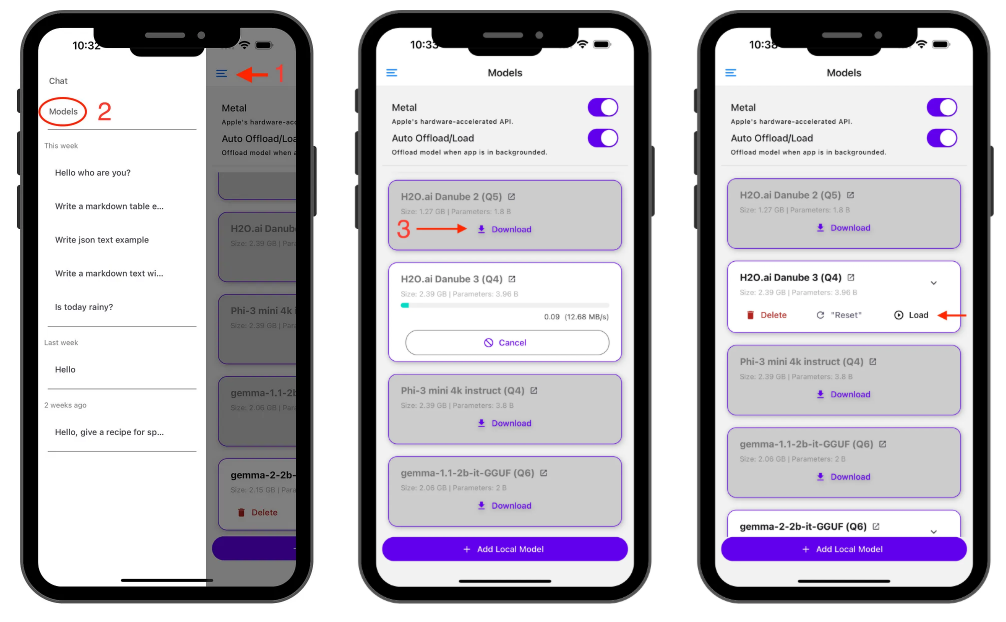
3、加载模型,下载后,点击 Load 将模型导入内存。现在您可以聊天了!
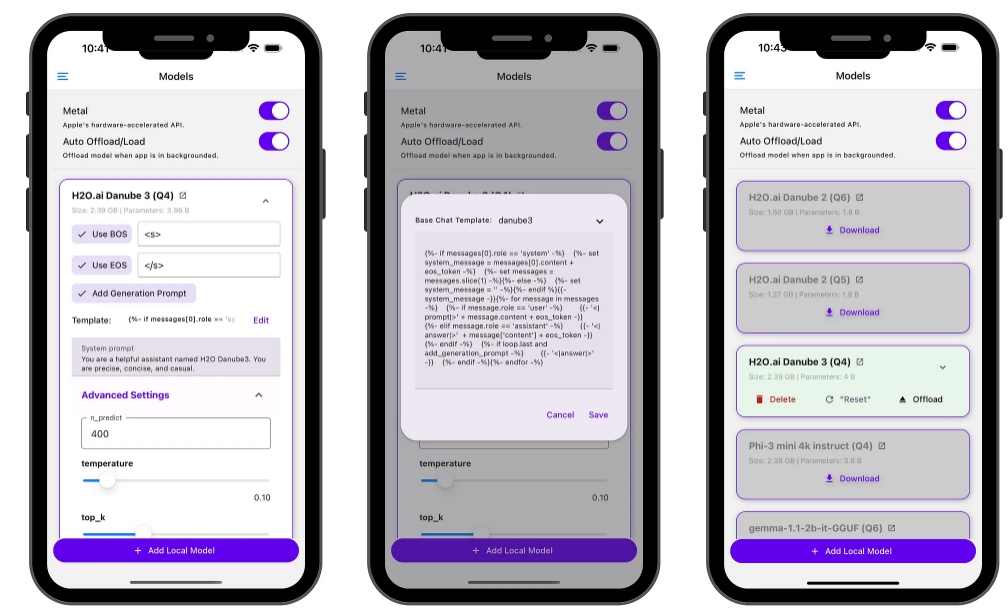
在 iOS 设备上,Apple 的 GPU API (Metal) 默认处于激活状态。如果您遇到任何问题,请尝试停用它。
iOS 金属
自动卸载/加载
为了保持设备平稳运行,PocketPal AI 可以自动管理内存使用情况:
在模型页面上启用 “Auto Offload/Load” (默认情况下是)
该应用程序将在后台卸载模型
当您返回时,它会重新加载(对于较大的模型,请等待几秒钟)
高级设置
单击 V 形图标可访问高级 LLM 设置,例如:
温度
BOS 代币
聊天模板选项等。
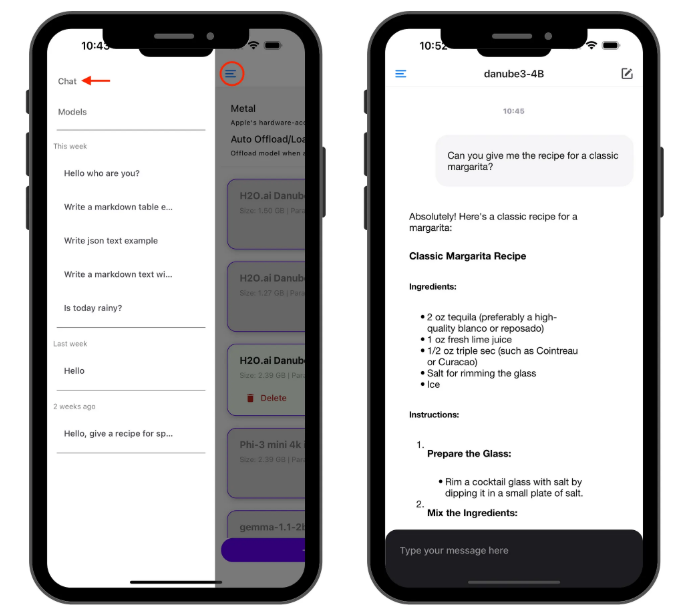
加载模型后,前往 “聊天” 页面并开始与加载的模型交谈!
此时还会显示 generation performance (生成性能) 指标。如果有兴趣,请观察聊天气泡以获取实时性能指标:每秒令牌数和每个令牌的毫秒数。
1、直接在您的设备上运行语言模型,无需互联网连接。
2、下载并在多个 SLM 之间进行交换,包括 Danube 2 和 3、Phi、Gemma 2 和 Qwen。
3、当应用程序在后台运行时,通过卸载模型来自动管理内存。
4、自定义模型参数,如系统提示符、温度、BOS 令牌和聊天模板。
1、袖珍型 AI 助手,由直接在手机上运行的小型语言模型 (SLM) 提供支持。
2、PocketPal AI 专为 iOS 和 Android 设计,让您无需互联网连接即可与各种 SLM 进行交互。
3、在 AI 响应生成期间查看每秒令牌数和每个令牌的毫秒数。










 角色扮演
角色扮演 模拟经营
模拟经营 冒险解密
冒险解密 体育竞技
体育竞技 动作格斗
动作格斗 休闲益智
休闲益智 飞行射击
飞行射击 音乐节奏
音乐节奏 回合制手游
回合制手游 传奇手游
传奇手游 网赚手游
网赚手游 手机游戏辅助
手机游戏辅助 网赚app
网赚app 漫画app
漫画app 直播平台
直播平台 旅游出行
旅游出行 网络购物
网络购物 教育培训
教育培训 新闻客户端
新闻客户端 社交平台
社交平台 金融理财
金融理财 拍照摄影
拍照摄影 学习阅读
学习阅读 办公必备
办公必备 生活应用
生活应用 手机工具
手机工具 聊天通讯
聊天通讯 影音媒体
影音媒体